Azure Language Service vs. LLM
This article explains the basic difference between using Azure AI Language Service compared to an LLM (Large Language Model) with a custom prompt.
Overview
Using Language Service with Azure Language Studio, the model can be setup to return the user’s intention based on utterances and entities used for training. It will then return a JSON result set as seen below.

JSON Result Returned:
{
"query": "I want to buy a car\n",
"prediction": {
"topIntent": "BuyCar",
"projectKind": "Conversation",
"intents": [
{
"category": "BuyCar",
"confidenceScore": 0.8265285
},
{
"category": "None",
"confidenceScore": 0
}
],
"entities": []
}
}
The same thing can be accomplished using an LLM in AI Foundry with a simple prompt:
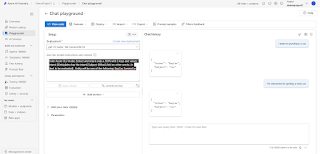
Question: What’s the advantage of using Language Service compared to an LLM if both can provide the same JSON results with LLM having less setup and configuration?
Answer:
Here are the key benefits of using Conversational Language Understanding (CLU) from the Language Service instead of an LLM for conversations:
- Determinism: Once trained, the output (both the prediction value and the JSON structure) for these custom CLU models are deterministic. There is no risk of hallucination which is more common with other LLMs.
- Low Latency: CLU models are lightweight and very fast, often providing a prediction in less than 50ms.
- Structured Output: Because CLU is designed for this specific conversational task, customers get a deterministic structured output with the custom intent categories, custom entity recognition, and prebuilt entity recognition.
- Evaluation Methods: CLU models provide confidence scores for the intent recognition, so customers can choose a confidence threshold for their implementation. CLU also provides detailed evaluation data, including precision, recall, and F1 scores, for testing.
- Predictable Costing: Once trained, CLU models are currently billed at a flat rate per 1000 utterances. So, billing is not dependent on a prompt or token size.
- Authoring Experience: CLU models can be designed, trained, and deployed directly in a tailored UX experience (in the AI Foundry on May 2025). This can also be done programmatically via our APIs.
- On-Prem Availability: CLU models can be hosted in connected and disconnected containers for customers who have on-premise needs.
As for the LLM approach, because LLMs don't require model training or labeling a training dataset, customers can see a decent quality model very quickly (provided that they have access to a high-quality prompt). LLMs are also context-aware and can maintain conversation context throughout a multi-turn conversation.
In my opinion, LLMs can be a great way to demonstrate the conversational AI capabilities at Microsoft, but we find that many customers are looking for more control over the output. Instead, customers often use LLMs to help support their CLU model construction. In fact, we have many more LLM-powered CLU capabilities in our roadmap for this year, including AOAI model deployments with the CLU structured output.
In addition, check out this video by Alan Smith that helps to sum it up.
Question: Building on the question above, why use Custom Question Answering (CQA) vs. LLMs with RAG (Retrieval Augmented Generation) ?
Answer:
CQA provides a lightweight knowledge base management experience that allows users to define specific answers for specific questions in a CQA project. Then at inference, it returns the exact answers for the question as defined in the project, instead of generative from knowledge base.
Benefits of CQA (in the context of LLMs + RAG):
This nature of CQA brings 2 key benefits:
- It ensures zero hallucination because it returns the exact answers as human authored in the project.
- The inference latency is very low because once the model identifies the question, it returns the full answer right away without generation time.
Key scenarios of using CQA (in the context of LLMs + RAG):
The benefits mentioned above optimizes the following key scenarios comparing LLMs with RAG:
- Answering critical questions where any hallucination is unacceptable (e.g. answers to policies, legal terms, etc.):
Given all answers in CQA are human reviewed/approved and be returned as it is. - Requiring timely fixes in answers (e.g. When generative answers from RAG are incorrect) that would have greater impact to customers and businesses:
In CQA it's simply about updating the answer and push to production deployment, comparing to RAG if something wrong it takes time to revisit the quality of the related documents, doc chunking and content retrieval mechanism, etc.
In addition, CQA and LLMs using RAG shouldn't been seen either-or options. They should be considered used together to complement each other. E.g.:
- Use CQA to cover critical questions to ensure zero hallucinations.
- Use RAG to cover most of the other questions (which usually is a long tail of all different kinds of questions users may ask that are hard to predict when designing the solution).
- Leverage CQA to quickly fix the quality issue from RAG of any important answers, esp. as discovered in production when time-to-resolution is critical.
Here's an accelerator project that demonstrates this orchestration: Azure-Samples/Azure-Language-OpenAI-Conversational-Agent-Accelerator: A solution accelerator project harnessing the capabilities of Azure AI Language to augment an existing Azure OpenAI RAG chat app. Utilize Conversational Language Understanding (CLU) and Custom Question Answering (CQA) to dynamically improve a RAG chat experience.

Comments
Post a Comment