User Groups
- Jul 11: DBA Fundamentals Group
- Jul 12: Azure Cleveland
- Jul 19: Akron Women in Tech
- Jul 20: Great Lakes User Group for .Net (GLUG.Net)
- Jul 27: Cleveland C#
Conferences
User Groups
Conferences
While attending a Microsoft Azure Fundamentals Training session today, some interesting questions were posted. Listed below is the Q&A from the forum:
1. How does private cloud differ from on-prem?
A private cloud may be hosted from your onsite datacenter, which would be on-premises. It may also be hosted in a dedicated datacenter offsite, potentially even by a third party that has dedicated that datacenter to your company. You can find more information here: https://learn.microsoft.com/en-us/training/modules/describe-cloud-compute/5-define-cloud-models
2. Which is cheaper, public or hybrid cloud?
This depends on how your organization is structured, the size, and the services you need. You can compare on-premises and cloud costs using the Total Cost of Ownership Calculator here: https://azure.microsoft.com/en-us/pricing/tco/
3. When to use private cloud (on prem) without [public] cloud ?
In some cases, your organization may be legally required to store information in your own data center. There may be other compliance and cost considerations as well. The size of your company and the resources you need may be less expensive in one form or another. You can find more information here: https://learn.microsoft.com/en-us/training/modules/describe-cloud-compute/5-define-cloud-models
4. Does Hybrid cloud incurs both capital and operational expenditure?
Yes, hybrid cloud incurs both capital and operational expenditure.
5. Is there any difference in availability of private and public cloud ?
There may be a difference in availability depending on the circumstances. If you have older technology in your private cloud, you may have more latency. Or, if you have resources on the other side of the globe in the public cloud, you may also have latency. There are many variables.
6. What’s the definition for public cloud?
A public cloud is built, controlled, and maintained by a third-party cloud provider. You can find more information here: https://learn.microsoft.com/en-us/training/modules/describe-cloud-compute/5-define-cloud-models
7. Does "Private Cloud" mean some form on on-prem Azure or AWS, etc.?
Azure and AWS are examples of Public Cloud. This is the opposite of private cloud. with Private cloud, you are owning/operating your own resources. With public cloud, your provider owns and operates the hardware. You can find more information here: https://learn.microsoft.com/en-us/training/modules/describe-cloud-compute/5-define-cloud-models
8. Would you explain the difference between elasticity and scalability?
Scalability means increasing or decreasing services as needed. Elasticity refers to enabling the increase or decrease of automatically: When a resource meets a limit, it will automatically increase as needed.
9. If I create a VM in Cloud, will I be charged even if VM is shut down?
Yes, because your VM is still taking up storage space. You will not be charged for run time if it is not running, though.
10. Does Azure provide private cloud capabilities if customer demands?
Yes, there are some options for organizations to have dedicated hardware. One example is with Azure dedicated host. More information about that is available here: https://learn.microsoft.com/en-us/azure/virtual-machines/dedicated-hosts
11. Please provide definition for CAPEX
CapEx refers to Capital Expenditure and is typically a one-time, up-front expenditure to purchase or secure tangible resources. A new building, repaving the parking lot, building a datacenter, or buying a company vehicle are examples of CapEx. You can find more information here: learn.microsoft.com/en-us/training/modules/describe-cloud-compute/6-describe-consumption-based-model
12. Do Microsoft Azure has a data center in the continent of Antarctica?
Great question. I don't see one in Antarctica. You can find the list here: https://azure.microsoft.com/en-us/explore/global-infrastructure/geographies/#choose-your-region
User Groups
Conferences
May 5: StirTrek
May 11-13: Global Azure 2023
May 20: Ohio North SQL Saturday
User Groups
Conferences
User Groups
Conferences
Use Azure Advisor to identify idle virtual machines (VMs), ExpressRoute circuits, and other unused resources.
Find resources not fully utilized with Azure Advisor. It will also provide recommendations on reconfiguring resources to reduce cost.
Use reservation pricing to pre-pay for resources for a 1 or 3 year term. This could result in a discount of up to 72% over pay-as-you-go pricing on Azure services.
Have existing on-premises software licenses? Use them with Azure for no additional cost and select Azure services for free.
Avoid the high cost of hardware investment used only during peak times of the year. Instead, dynamically allocate and de-allocate resources to match your business needs when you need it.
Use Microsoft Cost Management to create and manage budgets of Azure services used, and monitor your organization’s cloud spending.
Azure offers a variety of resources, with varying degrees of management. Depending on the level of resource management you choose, the monthly spend can be reduced significantly. Use the following diagrams to identify the various resources and management needs.
Diagram Reference: https://medium.com/chenjd-xyz/azure-fundamental-iaas-paas-saas-973e0c406de7
Overview
Speech services is one of the main categories of Azure Cognitive Services. Using this service, developers can utilize one of the four API’s to perform the following:
In a previous post, I wrote a tutorial on converting Speech-to-Text. For this post, I will go in the opposite direction and provide step-by-step directions to covert text-to-speech.
How to Use Text-to-Speech
The class “Program” contains 2 methods: Main() & CheckResult().
Breaking Down Main()
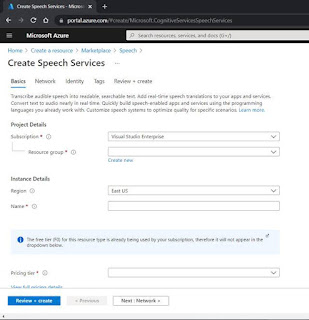
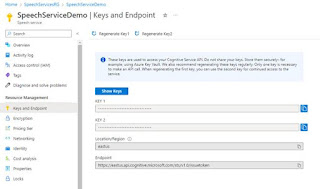
Looking at Main(), the first task is to obtain the Subscription key and region. These 2 values are obtained from Step 3 above, and are tied to the Azure subscription. They can be used by anyone who obtains them. For this reason, these items are stored in .Config file and not made available to the reader.
The next task is to instantiate SpeechConfig class using the subscription and region. The purpose of this class to contain all configuration for the Speech Service.
In addition to subscription and region, line 14 specifies the voice to be used for the speech synthesis. Azure Speech Service offers a variety of voices and supported languages, and can be found here.
After the speechConfig class is configured, it’s passed to the constructor of the SpeechSynthesizer class. As the name suggests, this class contains methods for synthesizing, or converting, text to speech. It utilizes all configuration settings specified in the prior steps.
In lines 17-26, an infinite while loop cycles through asking the user for text input, asynchronously calling the SpeakTextAsync() in the speechSynthesizer class.
speechSynthesizer.SpeakTextAsync() is an async method that takes the text string as an input parameter, sends it to Azure Speech Services to be synthesized as the desired spoken language, then plays the synthesized speech on the default speaker.
Breaking Down CheckResult()
This method is used for error checking the synthesis results and handling it accordingly. CheckResult() examines the results returned in the Reason property of the speechSynthesisResult instance. If synthesis completed successfully, it simply echoes the text entered. Otherwise if an error occurred, it will display the messages stored in the ErrorCode and ErrorDetails properties of the SpeechSynthesisCancellationDetails class.
A complete demo of Text-to-Speech service can be found in this segment.
Why use Text-to-Speech
The first reaction most developers have once they hear the results is “how cool is this?”. It’s certainly cool, but the benefits of this feature extend beyond a novelty. Applications can now verbally communicate results with visually impaired users, a segment of the user population that is often overlooked. Another benefit of verbal communication is allowing all users to hear results while doing other tasks instead of having to focus on a screen to read results. Text-to-Speech is 1 of 4 services in the Speech category of Cognitive Services.
A video presentation and demo on “Overview of Speech Services” discusses all the services in more detail. The corresponding code used for the video presentation and this article can be found at https://github.com/SamNasr/AzureSpeechServices.
This post was featured as part of the C# Advent 2022, an annual blogging event hosted by Matthew D. Groves.
During the last meeting of the .NET Study Group on Azure Virtual Networks, a couple questions came up that needed further explanation. I thought it would be best to post the and share them
Question: Do I need a NSG or Subnet if a VM is in VNet?
Answer: Yes, it’s a best practice. By default, services outside the VNet cannot connect to services within the VNet.
However, you can configure the network to allow access to the external service. Therefore, assume you have a VNet that contains both web servers and DB servers. You can have VNET configured for public access to allow outside users to access the web servers. You would also need a subnet or NSG to prevent that same public traffic from accessing the DB servers in the same VNet.
Question: Can you provide a sample diagram of the Azure Infrastructure and how VNets would be implemented?
Answer: See below for the Sample Azure Infrastructure Diagram: (https://www.dotnettricks.com/learn/azure/what-is-microsoft-azure-virtual-network-and-architecture)
Question: Where can I find a list of Frequently asked questions on Azure VNets?
Answer: For additional reading on Azure VNet, see the FAQ page at https://learn.microsoft.com/en-us/azure/virtual-network/virtual-networks-faq
User Groups
Conferences
User Groups
Conferences
User Groups
Conferences
User Groups
Conferences
Virtual User Group Meetings for Mar/Apr ‘22
Mar 24: “Predicting Flights with Azure Databricks” - https://www.meetup.com/NWVDNUG/events/284074689/
Mar 29: “Machine Learning in .Net” - https://www.meetup.com/Edmonton-NET-User-Group/events/284389088/
Apr 4: Ohio North Database Training- https://www.meetup.com/ohio-north-database-training/events/
Apr 13: Azure Cleveland - https://www.meetup.com/Azure-Cleveland-Meetup/
Apr 21: GLUG.Net - https://www.meetup.com/GLUGnet/events/
Apr 28: Cleveland C#/VB.Net User Group - https://www.meetup.com/Cleveland-C-VB-Net-User-Group
Virtual User Group Meetings
Microsoft’s Azure offers a great deal of features and capabilities. One of them is Cognitive Services, where users can access a variety of APIs to help mimic a human response. Some features include converting text to spoken speech, speech to text, and even the equivalent human understanding of a spoken phrase. These services are divided into 4 major categories, as seen below. Please note “Computer Vision” and “Custom Vision” sound very similar but their capabilities are different, as outlined in the “Vision” section below.
Decision
Language
Speech
Vision
Note: Model can be exported for use: https://docs.microsoft.com/en-us/azure/cognitive-services/custom-vision-service/export-your-model
Overview
Speech-to-text is one of the many cognitive services offered by Azure. All Azure cognitive services can be classified into one of four primary categories:
Each category contains a variety of services, with Speech-to-text categorized in the “Speech” category. It converts spoken language to text using either an SDK or web API call. Both methods will require a subscription key, obtained by a brief resource setup in the Azure portal. Speech-to-text can be configured to recognize a variety of languages as displayed at https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/language-support.
In addition, the source of the speech could be either live spoken words, or a recording.
How to Use Speech-to-text
Project Setup (using SDK)





Why you should use Speech-to-text?
Accessibility! Most applications depend on users not being vision impaired. However, this prevents a significant number of users from using an application due to their impaired vision. Certainly screen readers have been available in the Windows OS for nearly 2 decades. This allows any user to understand what is displayed on the screen. However, an impaired user will have difficulty interacting with the user interface (i.e. submitting info, filling forms, etc.). Thanks to Speech-to-text, users can now speak to the application and have the words dynamically translated to text in the application. This makes the application accessible to more users, as well as ADA and WCAG compliant.
Recently Vinod Kurpad delivered a presentation on using AI to build document processing workflows. The presentation slides can be found at https://on24static.akamaized.net/event/34/60/86/0/rt/1/documents/resourceList1636579433122/useaitobuilddocumentprocessingworkflows1636579401517.pdf
By using AI, several boxed fields (i.e. SSN) on a forma can be treated as 1 field. It allows dynamic entities, like tables, to recognize multiple rows in a single table with various column types.
Listed below are questions and answers discussed during the presentation:
Form Recognizer is available in Power Apps and has a receipt processing app in Power Apps. Licensing model in this scenario is via Power Apps. https://powerapps.microsoft.com/en-us/blog/process-receipts-with-ai-builder/
Not yet, Layout currently supports text, checkboxes, selection marks and reading order. Paragraphs, headers and more are on the roadmap.
Currently the only supported format is JSON. But there are a number of JSON to XML converters that should enable you to convert the output to XML
Reading order already supports multiple columns. Try it out :)
Form Recognizer receipts returns all line items, date, total etc. You can write validations and additional logics on top of the output as post processing. See here for all fields extracted from receipts - https://docs.microsoft.com/en-us/azure/applied-ai-services/form-recognizer/concept-receipt
It's on the roadmap for a preview in the first half of next year.
https://customers.microsoft.com/en-us/story/financial-fabric-banking-capital-markets-azure
When using Form Recognizer no pre-processing of the images are needed. It supports low dpi and various image qualities.
Yes, a key value pair can also be a value with no explicitly labeled key, but a span of text that describes the value.
Yes, Form Recognizer supports handwritten in the following languages - English, Simplified Chinese, French, German, Italian, Portuguese, Spanish. see all supported languages printed and handwritten here - https://docs.microsoft.com/en-us/azure/applied-ai-services/form-recognizer/language-support
https://docs.microsoft.com/en-us/azure/applied-ai-services/form-recognizer/language-support
Form Recognizer supports the following file formats - PDF (digital and scanned and multi-page), Tiff, bmp, jpg, png
Yes it does. No pre-processing needed. Please send the source document to Form Recognizer as is and Form Recognizer will do all the work for you.
Cognitive Services also includes speech to text and transcription APIs that you can combine for interviews.
Try creating a resource with a different name and see if that helps- the Studio is continually improving after the recent preview. Also send an email to formrecog_contact@microsoft.com
Form Recognizer includes signature detection capability, you can train a model to detect if a signature is detected or not.
The Form Recognizer features (APIs) build on top of OCR and handle digital, images and hybrid documents transparently.
The demo showed the specific document rendered in the browser, you can add a URL field to the index which is a pointer to the location of the original document
Not yet, on our roadmap but not available yet. Currently you should split the document into pages in such case and send the individual pages to Form Recognizer and then unite them in post processing. For invoices and line items tables that span multiple pages are supported.
Yes, Form Recognizer enables opening an FOTT project and Form Recognizer supports backward compatibility and you can use 2.1 release models in the new release also.
If you know the different form types you expect to receive, you should be able to train a model for each form and compose all the individual models into a single logical model. Sending a document to this logical model will result in the document being classified to determine the right model to extract the fields. The selected model is also returned as part of the response
No data can be anywhere and you can stream the document to Form Recognizer for analyzing or send a URL. Only your training data to train a custom model needs to be in a blob and only 5 documents are needed to get started with custom and train your own model
Max file size is 50MB currently.
The Studio and the underlying files handle multi-page labels and navigating across pages to label the data you want to extract.
To train a model all documents within a project and a model needs to be from the same type, same format. You can then compose several models into a model composed so you do not need to classify the document before sending it to Form Recognizer. You need 5 forms from the same type to train a model.
Form Recognizer text extraction supports print and handwritten and we just expanded handwritten from English to Simplified Chinese, French, Italian, Spanish, German, and Portuguese
Yes, Form Recognizer supports multipage documents.
Form Recognizer is the resource you need to create in the portal
The previous version of the labeling tool that's now superseded by the new Form Recognizer Studio -https://fott-2-1.azurewebsites.net/
Layout extracts tables as they appear on the document and will try to extract all rows and columns including indicate merged rows and columns spans. When labeling tables if the table changes and has a variety numbers or rows or columns you can label it as a dynamic table.
Yes, Form Recognizer supports handwritten text in the following languages - English, Simplified Chinese, French, German, Italian, Portuguese, Spanish. see all supported languages printed and handwritten here - https://docs.microsoft.com/en-us/azure/applied-ai-services/form-recognizer/language-support
Connect to the same blob storage and the project will open with all the data and labeling completed.
AI Builder which is a part of the Power Automate stack uses Form Recognizer and you should be able to use the same set of capabilities in AI Builder as well.
We suggest benchmarking it on your content but we believe and customers have validated that the handwritten OCR is world class for the supported languages, and yes Form Recognizer and OCR tech are heavily used in healthcare and financial verticals that involve processing handwritten text
When training a custom model if the variations are slight a key name changed, moved etc. than Form Recognizer should be able to extract, if you see that it misses than you can add a few documents with the variation to the model and improve the model. If the variation is big than you should train a model per year and then compose them to a model composed.
You can start with the documentation https://docs.microsoft.com/en-us/azure/applied-ai-services/form-recognizer/ . Also note that Form Recognizer supports a free tier which should allow you to test all the different features without paying for it
Yes! Form Recognizer supports a few different languages with an SDK, but the REST API is available for languages not supported by an SDK
Form Recognizer supports split cells, merged cells tables with no borders and complex tables. See more details on table extraction int he following blog https://techcommunity.microsoft.com/t5/azure-ai/enhanced-table-extraction-from-documents-with-form-recognizer/ba-p/2058011
If you mean concatenated or complex tables, then yes, we are continuously improving on extracting those. On the other hand, table extraction supports tables with or without physical lines.
Form Recognizer is integrating within Power Apps see Form Processing apps. In reference to another 365 domain can you please reach out to Form Recognizer Contact Us and we can try to assist
On October 28, 2021, Jeff Fritz (Microsoft) presented “What’s new in .Net 6” to the Cleveland C#/VB.Net User Group.
A recording of that presentation is now available here on my YouTube Channel.
Listed below is a brief summary of the key points from that presentation.
C#10
Blazor
.Net Release and LTS (Long Term Support) Schedule

Resources